
-
1. Gitを始めるにあたって
- 1.1 バージョン管理について
- 1.2 Gitの歴史
- 1.3 Gitとは何か?
- 1.4 コマンドライン
- 1.5 Gitのインストール
- 1.6 Gitの初回セットアップ
- 1.7 ヘルプの利用
- 1.8 まとめ
-
2. Gitの基本
- 2.1 Gitリポジトリの取得
- 2.2 リポジトリへの変更の記録
- 2.3 コミット履歴の表示
- 2.4 元に戻す操作
- 2.5 リモートでの作業
- 2.6 タグ付け
- 2.7 Gitエイリアス
- 2.8 まとめ
-
3. Gitのブランチ機能
- 3.1 ブランチの基本
- 3.2 基本的なブランチとマージ
- 3.3 ブランチ管理
- 3.4 ブランチワークフロー
- 3.5 リモートブランチ
- 3.6 リベース
- 3.7 まとめ
-
4. サーバー上のGit
- 4.1 プロトコル
- 4.2 サーバーにGitをセットアップする
- 4.3 SSH公開鍵の生成
- 4.4 サーバーのセットアップ
- 4.5 Gitデーモン
- 4.6 スマートHTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 サードパーティのホスティングオプション
- 4.10 まとめ
-
5. 分散Git
- 5.1 分散ワークフロー
- 5.2 プロジェクトへの貢献
- 5.3 プロジェクトの管理
- 5.4 まとめ
-
6. GitHub
- 6.1 アカウントのセットアップと設定
- 6.2 プロジェクトへの貢献
- 6.3 プロジェクトの管理
- 6.4 組織の管理
- 6.5 GitHubのスクリプト
- 6.6 まとめ
-
7. Gitツール
- 7.1 リビジョンの選択
- 7.2 インタラクティブステージング
- 7.3 スタッシュとクリーン
- 7.4 作業に署名する
- 7.5 検索
- 7.6 履歴の書き換え
- 7.7 Resetの解明
- 7.8 高度なマージ
- 7.9 Rerere
- 7.10 Gitを使ったデバッグ
- 7.11 サブモジュール
- 7.12 バンドル
- 7.13 置換
- 7.14 認証情報の保存
- 7.15 まとめ
-
8. Gitのカスタマイズ
- 8.1 Gitの設定
- 8.2 Git属性
- 8.3 Gitフック
- 8.4 Gitによるポリシー適用例
- 8.5 まとめ
-
9. Gitと他のシステム
- 9.1 クライアントとしてのGit
- 9.2 Gitへの移行
- 9.3 まとめ
-
10. Gitの内側
- 10.1 PlumbingとPorcelain
- 10.2 Git オブジェクト
- 10.3 Gitリファレンス
- 10.4 Packfile
- 10.5 Refspec
- 10.6 転送プロトコル
- 10.7 メンテナンスとデータ復旧
- 10.8 環境変数
- 10.9 まとめ
-
A1. 付録A: 他の環境でのGit
- A1.1 グラフィカルインターフェース
- A1.2 Visual StudioでのGit
- A1.3 Visual Studio CodeでのGit
- A1.4 IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMineでのGit
- A1.5 Sublime TextでのGit
- A1.6 BashでのGit
- A1.7 ZshでのGit
- A1.8 PowerShellでのGit
- A1.9 まとめ
-
A2. 付録B: アプリケーションへのGitの組み込み
- A2.1 コマンドラインGit
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
A3. 付録C: Gitコマンド
- A3.1 セットアップと設定
- A3.2 プロジェクトの取得と作成
- A3.3 基本的なスナップショット
- A3.4 ブランチとマージ
- A3.5 プロジェクトの共有と更新
- A3.6 検査と比較
- A3.7 デバッグ
- A3.8 パッチ適用
- A3.9 メール
- A3.10 外部システム
- A3.11 管理
- A3.12 Plumbingコマンド
10.2 Git の内部構造 - Git オブジェクト
Git オブジェクト
Git はコンテンツアドレス型ファイルシステムです。これはどういう意味でしょうか? Git の核となるのは、シンプルなキー・バリュー型のデータストアだということです。つまり、あらゆる種類のコンテンツを Git リポジトリに挿入でき、Git は後でそのコンテンツを取得するために使える一意のキーを返してくれます。
デモンストレーションとして、いくつかのデータを受け取り、それを .git/objects ディレクトリ (オブジェクトデータベース) に保存し、そのデータオブジェクトを参照する一意のキーを返すプラミングコマンド git hash-object を見てみましょう。
まず、新しい Git リポジトリを初期化し、objects ディレクトリには (当然ながら) 何もないことを確認します。
$ git init test
Initialized empty Git repository in /tmp/test/.git/
$ cd test
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type fGit は objects ディレクトリを初期化し、その中に pack および info サブディレクトリを作成しましたが、通常のファイルはありません。では、git hash-object を使って新しいデータオブジェクトを作成し、それを手動で新しい Git データベースに保存してみましょう。
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4最も単純な形式では、git hash-object は渡されたコンテンツを受け取り、Git データベースにそれを保存するために使われるであろう一意のキーを返すだけです。-w オプションは、キーを返すだけでなく、そのオブジェクトをデータベースに書き込むようにコマンドに指示します。最後に、--stdin オプションは git hash-object に処理するコンテンツを標準入力から取得するように指示します。そうしないと、コマンドは使用するコンテンツを含むファイル名引数をコマンドの最後に期待します。
上記のコマンドからの出力は、40文字のチェックサムハッシュです。これは SHA-1 ハッシュです。これは、保存しているコンテンツとヘッダーのチェックサムであり、これについては後ほど説明します。これで、Git がデータをどのように保存したかを確認できます。
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4objects ディレクトリをもう一度調べると、新しいコンテンツのファイルが含まれていることがわかります。これは Git が最初にコンテンツを保存する方法です。コンテンツごとに単一のファイルとして保存され、コンテンツとそのヘッダーの SHA-1 チェックサムで名前が付けられます。サブディレクトリは SHA-1 の最初の2文字で名前が付けられ、ファイル名は残りの38文字です。
オブジェクトデータベースにコンテンツがある場合、git cat-file コマンドでそのコンテンツを調べることができます。このコマンドは、Git オブジェクトを検査するための万能ツールのようなものです。cat-file に -p を渡すと、コマンドはまずコンテンツのタイプを判別し、次に適切に表示するように指示します。
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test contentこれで、Git にコンテンツを追加して、再度取り出すことができます。ファイル内のコンテンツでもこれを行うことができます。たとえば、ファイルに対して簡単なバージョン管理を行うことができます。まず、新しいファイルを作成し、そのコンテンツをデータベースに保存します。
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30次に、ファイルに新しいコンテンツを書き込み、再度保存します。
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3aオブジェクトデータベースには、この新しいファイルの両方のバージョン (および以前に保存した最初のコンテンツ) が含まれています。
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4この時点で、test.txt ファイルのローカルコピーを削除し、Git を使用して、オブジェクトデータベースから、保存した最初のバージョンを取得できます。
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1または2番目のバージョン
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2しかし、ファイルの各バージョンの SHA-1 キーを覚えるのは実用的ではありません。さらに、システムにファイル名を保存しているわけではなく、コンテンツだけです。このオブジェクトタイプはblobと呼ばれます。Git のオブジェクトの SHA-1 キーが与えられれば、git cat-file -t を使って、Git に任意のオブジェクトのオブジェクトタイプを教えてもらうことができます。
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blobツリーオブジェクト
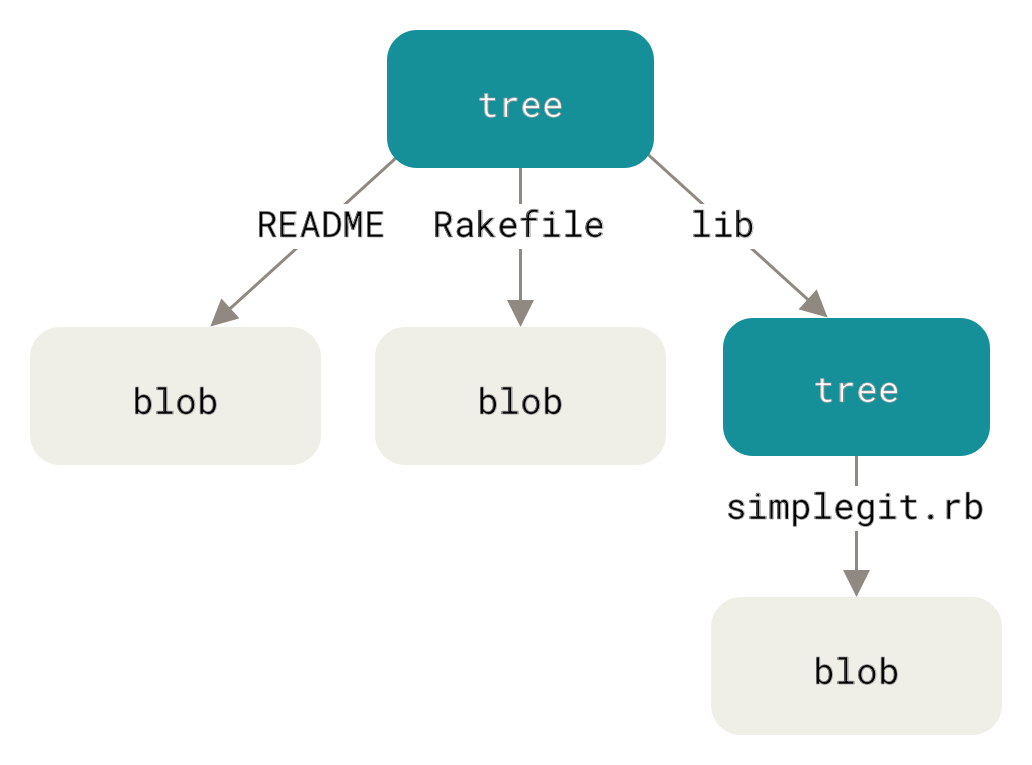
次に調べる Git オブジェクトのタイプはツリーです。これはファイル名を保存する問題を解決し、ファイルのグループをまとめて保存することも可能にします。Git は UNIX ファイルシステムに似た方法でコンテンツを保存しますが、少し簡略化されています。すべてのコンテンツはツリーオブジェクトとブロブオブジェクトとして保存され、ツリーは UNIX ディレクトリのエントリに対応し、ブロブは inode またはファイルコンテンツに多かれ少なかれ対応します。単一のツリーオブジェクトには1つ以上のエントリが含まれ、それぞれがブロブまたはサブツリーの SHA-1 ハッシュであり、それに関連付けられたモード、タイプ、およびファイル名が含まれます。たとえば、最新のツリーが次のようなプロジェクトを持っているとしましょう。
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 libmaster^{tree} 構文は、master ブランチ上の最後のコミットが指すツリーオブジェクトを指定します。lib サブディレクトリがブロブではなく、別のツリーへのポインタであることに注目してください。
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb|
注
|
使用しているシェルによっては、 Windows の CMD では、 ZSH を使用している場合、 |
概念的には、Git が格納しているデータは次のようになります。
自分でツリーを作成するのはかなり簡単です。Git は通常、ステージングエリアまたはインデックスの状態を取り込み、そこから一連のツリーオブジェクトを書き出すことでツリーを作成します。したがって、ツリーオブジェクトを作成するには、まずファイルをステージングしてインデックスを設定する必要があります。単一のエントリ (test.txt ファイルの最初のバージョン) を持つインデックスを作成するには、プラミングコマンド git update-index を使用できます。このコマンドを使用して、test.txt ファイルの以前のバージョンを新しいステージングエリアに人為的に追加します。ファイルがまだステージングエリアに存在しない (ステージングエリアさえまだ設定されていない) ため --add オプションを渡し、追加するファイルがディレクトリではなくデータベースにあるため --cacheinfo を渡す必要があります。次に、モード、SHA-1、およびファイル名を指定します。
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txtこの場合、モードとして 100644 を指定しています。これは通常のファイルであることを意味します。その他のオプションは、実行可能ファイルであることを意味する 100755 と、シンボリックリンクを指定する 120000 です。モードは通常の UNIX モードから取られていますが、はるかに柔軟性がありません。これらの3つのモードのみが Git のファイル (ブロブ) に対して有効です (ただし、ディレクトリやサブモジュールには他のモードが使用されます)。
これで、git write-tree を使用して、ステージングエリアをツリーオブジェクトに書き出すことができます。-w オプションは必要ありません。このコマンドを呼び出すと、そのツリーがまだ存在しない場合、インデックスの状態から自動的にツリーオブジェクトが作成されます。
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt以前に見たのと同じ git cat-file コマンドを使用して、これがツリーオブジェクトであることを確認することもできます。
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
tree次に、test.txt の2番目のバージョンと新しいファイルも含む新しいツリーを作成します。
$ echo 'new file' > new.txt
$ git update-index --cacheinfo 100644 \
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
$ git update-index --add new.txtステージングエリアには、test.txt の新しいバージョンと新しいファイル new.txt が含まれています。そのツリーを書き出し (ステージングエリアまたはインデックスの状態をツリーオブジェクトに記録し)、それがどのように見えるかを見てみましょう。
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
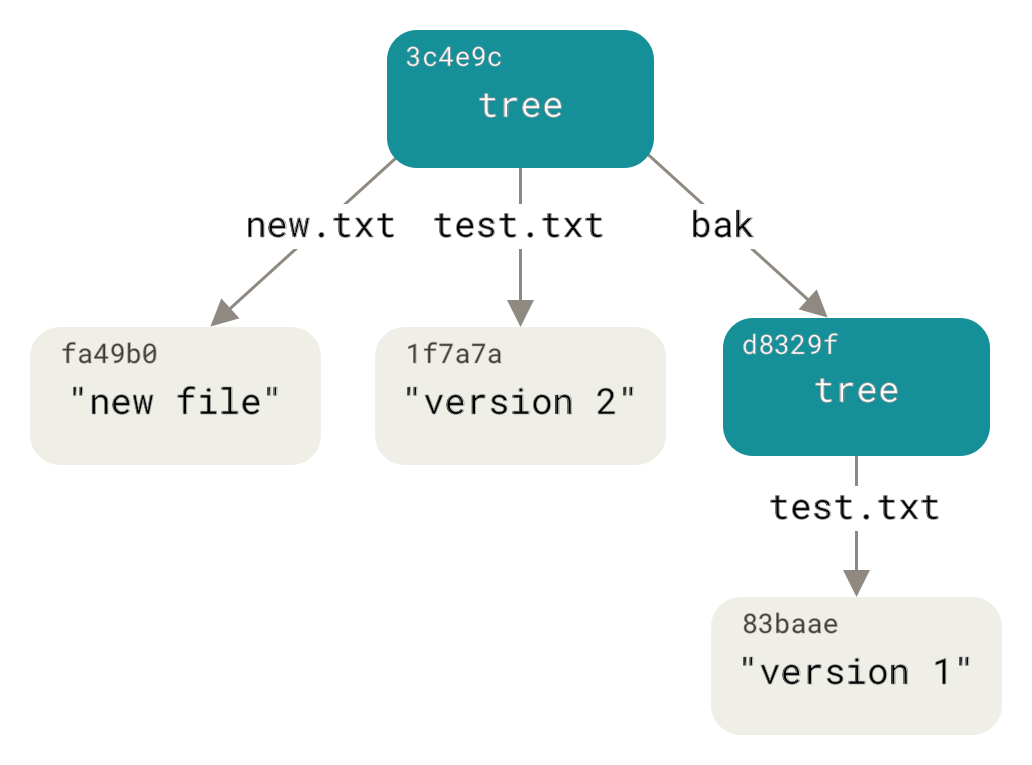
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtこのツリーには両方のファイルエントリがあり、test.txt の SHA-1 が以前の「バージョン2」の SHA-1 (1f7a7a) であることに注目してください。試しに、最初のツリーをこのツリーのサブディレクトリとして追加してみましょう。git read-tree を呼び出すことで、ツリーをステージングエリアに読み込むことができます。この場合、--prefix オプションをこのコマンドと一緒に使用することで、既存のツリーをステージングエリアにサブツリーとして読み込むことができます。
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt今書き込んだ新しいツリーから作業ディレクトリを作成した場合、作業ディレクトリの最上位に2つのファイルと、test.txt ファイルの最初のバージョンを含む bak というサブディレクトリが作成されます。Git がこれらの構造のために保持しているデータは次のようだと考えることができます。
コミットオブジェクト
上記のすべてを行った場合、プロジェクトの異なるスナップショットを表す3つのツリーができたことになりますが、以前の問題は残っています。スナップショットを呼び出すためには、3つの SHA-1 値すべてを覚えておく必要があります。また、誰がスナップショットを保存したか、いつ保存されたか、なぜ保存されたかについての情報もありません。これらは、コミットオブジェクトが保存する基本的な情報です。
コミットオブジェクトを作成するには、commit-tree を呼び出し、単一のツリー SHA-1 と、先行するコミットオブジェクトがある場合はそれを指定します。最初に書き込んだツリーから始めます。
$ echo 'First commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3d|
注
|
作成時間や作成者データが異なるため、異なるハッシュ値が得られます。さらに、原則として、任意のコミットオブジェクトは与えられたデータから正確に再現できますが、この本の構成の歴史的な詳細により、印刷されたコミットハッシュは与えられたコミットに対応しない場合があります。この章のさらに後で、コミットとタグのハッシュを自身のチェックサムに置き換えてください。 |
これで、git cat-file で新しいコミットオブジェクトを見ることができます。
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
First commitコミットオブジェクトの形式は単純です。その時点でのプロジェクトのスナップショットのトップレベルツリーを指定します。親コミットがあればそれも指定します(上記のコミットオブジェクトには親はありません)。作成者/コミッター情報(user.name と user.email の設定とタイムスタンプを使用)と空白行、そしてコミットメッセージです。
次に、他の2つのコミットオブジェクトを書き込みます。それぞれが直前のコミットを参照します。
$ echo 'Second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'Third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe93つのコミットオブジェクトはそれぞれ、作成した3つのスナップショットツリーのいずれかを指しています。不思議なことに、最後のコミット SHA-1 で git log コマンドを実行すると、実際の Git ヒストリを見ることができます。
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
Third commit
bak/test.txt | 1 +
1 file changed, 1 insertion(+)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
Second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
First commit
test.txt | 1 +
1 file changed, 1 insertion(+)素晴らしい。フロントエンドコマンドを使わずに、Git ヒストリを構築するための低レベル操作を完了しました。これは、git add および git commit コマンドを実行するときに Git が本質的に行っていることです。変更されたファイル用のブロブを保存し、インデックスを更新し、ツリーを書き出し、トップレベルツリーと直前のコミットを参照するコミットオブジェクトを書き出します。これら3つの主要な Git オブジェクト(ブロブ、ツリー、コミット)は、最初は .git/objects ディレクトリに個別のファイルとして保存されます。これが、例のディレクトリにあるすべてのオブジェクトで、何が保存されているかをコメントで示しています。
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1すべての内部ポインタをたどると、次のようなオブジェクトグラフが得られます。
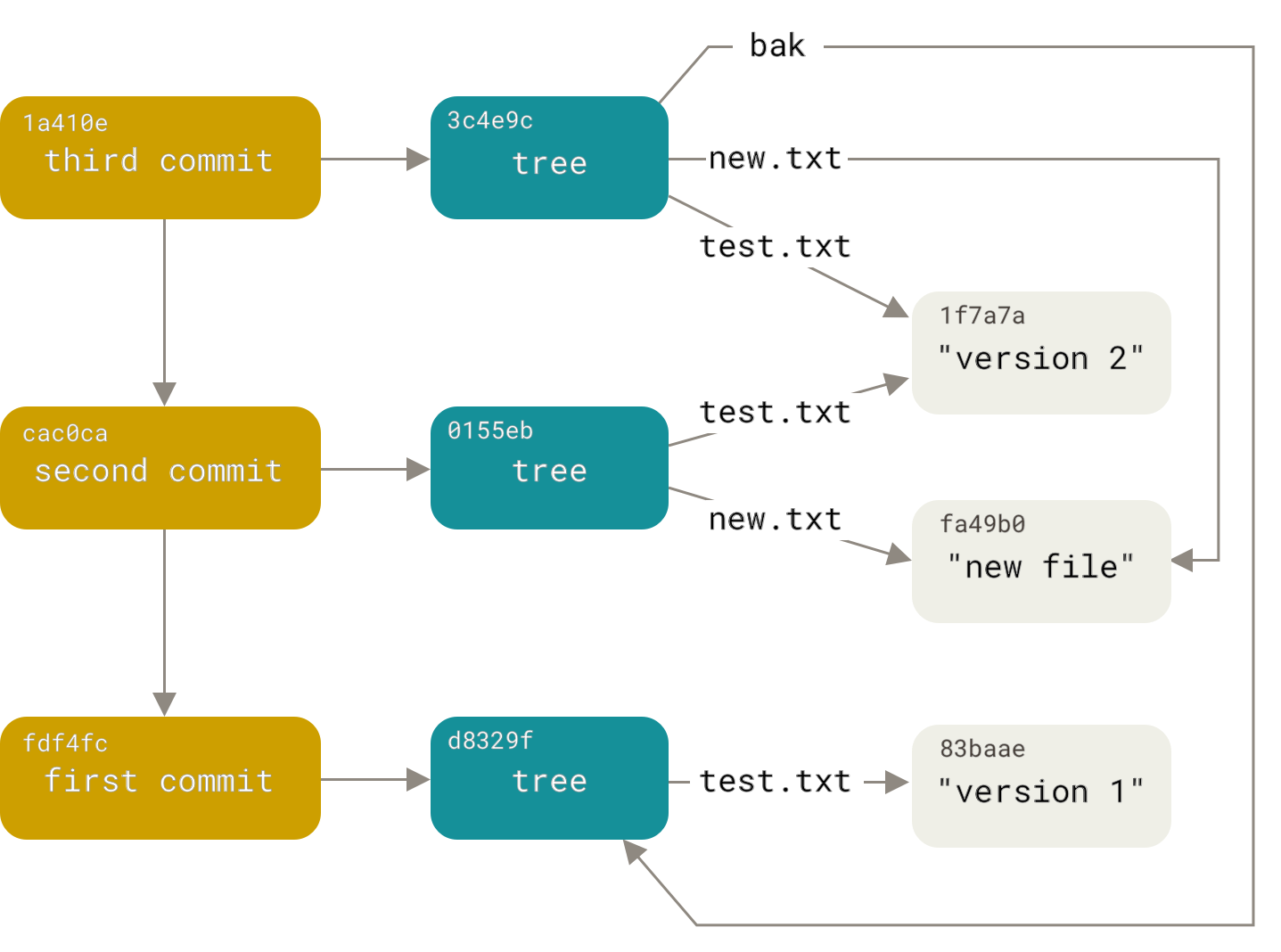
オブジェクトストレージ
以前、Git オブジェクトデータベースにコミットするすべてのオブジェクトにはヘッダーが格納されていると述べました。Git がオブジェクトをどのように保存するかを見てみましょう。ここでは、文字列「what is up, doc?」を Ruby スクリプト言語でインタラクティブにブロブオブジェクトとして保存する方法を説明します。
irb コマンドでインタラクティブな Ruby モードを開始できます。
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"Git はまず、オブジェクトのタイプ(この場合はブロブ)を識別するヘッダーを構築します。そのヘッダーの最初の部分に、Git はスペースとコンテンツのバイトサイズを追加し、最後にヌルバイトを追加します。
>> header = "blob #{content.bytesize}\0"
=> "blob 16\u0000"Git はヘッダーと元のコンテンツを連結し、その新しいコンテンツの SHA-1 チェックサムを計算します。Ruby で文字列の SHA-1 値を計算するには、require コマンドで SHA1 ダイジェストライブラリをインクルードし、文字列を引数として Digest::SHA1.hexdigest() を呼び出します。
>> store = header + content
=> "blob 16\u0000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"これを git hash-object の出力と比較してみましょう。ここでは、入力に改行を追加しないように echo -n を使用しています。
$ echo -n "what is up, doc?" | git hash-object --stdin
bd9dbf5aae1a3862dd1526723246b20206e5fc37Git は zlib で新しいコンテンツを圧縮します。これは Ruby の zlib ライブラリで行うことができます。まず、ライブラリを require し、次にコンテンツに対して Zlib::Deflate.deflate() を実行します。
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\x9CK\xCA\xC9OR04c(\xCFH,Q\xC8,V(-\xD0QH\xC9O\xB6\a\x00_\x1C\a\x9D"最後に、zlib で圧縮したコンテンツをディスク上のオブジェクトに書き込みます。書き出すオブジェクトのパスを決定します (SHA-1 値の最初の2文字がサブディレクトリ名、残りの38文字がそのディレクトリ内のファイル名です)。Ruby では、FileUtils.mkdir_p() 関数を使用して、サブディレクトリが存在しない場合に作成できます。次に、File.open() でファイルを開き、以前に zlib で圧縮したコンテンツを、結果のファイルハンドルで write() を呼び出してファイルに書き込みます。
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32git cat-file を使用してオブジェクトのコンテンツを確認してみましょう。
---
$ git cat-file -p bd9dbf5aae1a3862dd1526723246b20206e5fc37
what is up, doc?
---これで、有効な Git ブロブオブジェクトが作成されました。
すべての Git オブジェクトは同じ方法で保存されますが、タイプが異なります。文字列「blob」の代わりに、ヘッダーは「commit」または「tree」で始まります。また、ブロブのコンテンツはほとんど何でも構いませんが、コミットとツリーのコンテンツは非常に特定の方法でフォーマットされています。